大数据技术基础笔记(一) 大数据概述与处理技术
一、大数据概述
随着信息技术的飞速发展,数据已成为当今社会的新型生产要素和重要战略资源。大数据(Big Data),顾名思义,是指规模巨大、类型复杂、处理难度超出传统数据库软件工具能力范围的数据集合。其核心价值在于通过新的处理模式,挖掘出更强的决策力、洞察发现力和流程优化能力。
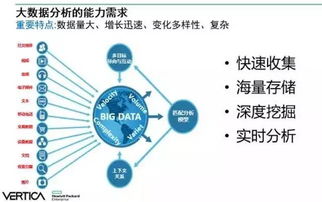
大数据通常以“5V”特征来定义:
- Volume(大量):数据体量巨大,从TB级别跃升到PB甚至EB级别。
- Velocity(高速):数据生成、处理和分析的速度要求极高,往往需要实时或准实时响应。
- Variety(多样):数据类型繁多,包括结构化数据(如数据库表)、半结构化数据(如XML、JSON日志)和非结构化数据(如文本、图片、视频、音频)。
- Value(低价值密度):海量数据中真正有价值的信息比例可能很低,需要通过强大的算法进行“提纯”。
- Veracity(真实性):数据的质量和可信赖度,处理过程中需关注数据的准确性和一致性。
大数据的应用已渗透到各行各业,如金融风控、智慧城市、精准医疗、推荐系统、物联网等,深刻改变着社会生产和生活方式。
二、大数据处理技术
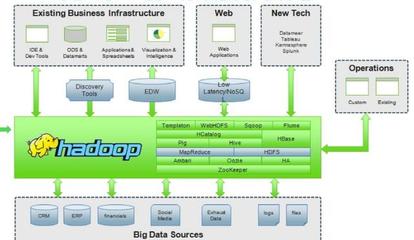
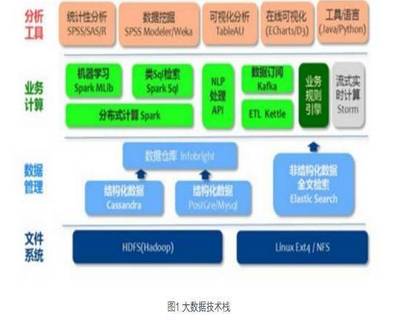
面对大数据的“5V”挑战,传统的数据处理架构(如单机关系型数据库)已力不从心。因此,一系列以分布式、并行计算为核心的大数据处理技术应运而生,形成了完整的技术生态体系。其核心处理流程可概括为:数据采集与存储 -> 数据计算与分析 -> 数据应用与服务。
1. 数据采集与存储技术
此阶段是基石,旨在将海量、多源的数据可靠地汇聚并存储起来。
- 采集技术:如Flume(日志采集)、Sqoop(关系数据库与Hadoop间数据传输)、Kafka(高吞吐分布式消息队列,用于实时数据流采集)。
- 存储技术:核心是分布式文件系统和分布式数据库。
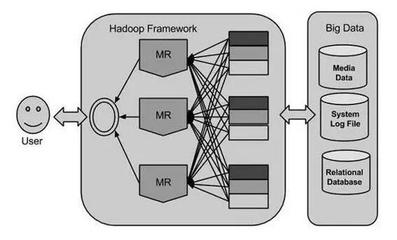
- HDFS(Hadoop Distributed File System):Hadoop生态的基石,能将超大文件分布式存储在普通服务器集群上,提供高容错性和高吞吐量。
- NoSQL数据库:为处理多样、灵活的非关系型数据而生,如键值型(Redis)、文档型(MongoDB)、列族型(HBase)、图数据库(Neo4j)。
- NewSQL数据库:试图兼具NoSQL的扩展性与传统关系型数据库的ACID事务特性,如Google Spanner、TiDB。
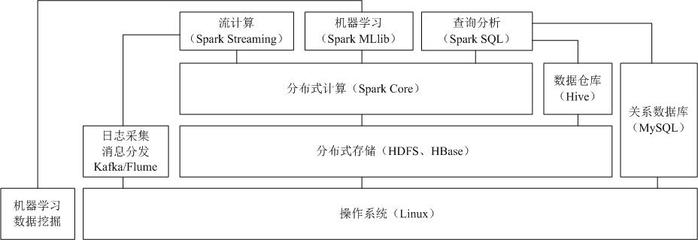
2. 数据计算与分析技术
这是挖掘数据价值的核心环节,分为批处理和流处理两种模式。
- 批处理技术:针对静态的、历史的海量数据集进行计算,特点是高吞吐、延迟较高。
- MapReduce:最早期的分布式计算编程模型,将计算任务分为Map(映射)和Reduce(归约)两个阶段,但编程复杂、I/O开销大。
- Apache Spark:当前主流批处理框架。它基于内存计算,通过弹性分布式数据集(RDD)提供了比MapReduce快数十倍的计算速度,同时支持流处理、图计算和机器学习。
- 流处理技术:针对持续不断产生的实时数据流进行计算,特点是低延迟、高时效。
- Apache Storm:早期的流处理框架,保证每条消息都被处理,延迟在毫秒级。
- Apache Flink:新一代流处理引擎,将流处理视为根本,同时完美支持批处理(视作有界流)。它提供了精确一次(Exactly-Once)的状态一致性保证,在实时计算领域势头强劲。
- Spark Streaming:基于Spark的微批处理(Micro-Batch)模型,将实时流数据切分成小批次进行处理。
3. 资源管理与协调技术
为上层计算框架提供统一的集群资源管理、调度和协调服务。
- Apache Hadoop YARN:Hadoop 2.0引入的核心组件,将资源管理与作业调度/监控分离,成为一个通用的集群资源管理系统,允许Spark、Flink等多种计算框架运行其上。
- Apache Mesos:另一款开源的集群管理器,能高效地抽象和调度CPU、内存、存储等资源。
- Kubernetes:源自谷歌的容器编排系统,如今也越来越多地用于部署和管理大数据工作负载,成为云原生大数据架构的重要选择。
4. 数据查询与分析工具
为了让数据分析师和业务人员更方便地使用数据,出现了多种查询引擎和工具。
- Hive:基于Hadoop的数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类似SQL的HiveQL查询语言,底层转换为MapReduce/Spark/Tez作业执行,降低了使用门槛。
- Impala/Presto/Drill:这些是交互式查询引擎,支持对HDFS、HBase等数据源进行快速的、低延迟的SQL查询,无需将SQL转换为沉重的MapReduce作业,更适合即席查询。
5. 数据处理架构演进
从早期的Lambda架构(同时维护批处理和流处理两套代码路径以平衡延迟与准确性)到如今的Kappa架构(主张所有数据都通过流处理,历史数据通过重播流来模拟批处理),再到以Flink为代表的流批一体架构,技术趋势是简化架构、降低维护成本,并追求更极致的实时性。
****:大数据技术是一个庞大且快速演进的生态系统。理解从数据采集存储到计算应用的全流程,掌握以HDFS、Spark、Flink等为代表的核心组件及其适用场景,是构建高效、可靠大数据处理平台的基础。后续笔记将对其中的关键技术进行更深入的探讨。
如若转载,请注明出处:http://www.sdlysll.com/product/27.html
更新时间:2026-04-22 19:58:48