大数据处理技术Spark 课程资源建设与教学实践探索——基于林子雨教授的报告分享
在当前数据驱动发展的时代背景下,大数据处理技术已成为计算机科学与数据科学领域的核心技能之一。Apache Spark作为新一代高效、通用的大数据处理引擎,凭借其内存计算、易用性和丰富的生态系统,在学术界和工业界均获得了广泛应用。厦门大学林子雨副教授长期致力于大数据与Spark技术的教学与推广,其团队建设的课程资源与积累的教学经验,为相关领域的人才培养提供了宝贵参考。
一、Spark课程资源体系建设
林子雨团队构建了多层次、立体化的Spark课程资源体系,其核心特点在于“开源开放、持续更新、循序渐进”。
- 主教材与在线教程:编写并开源了《Spark编程基础》等系列教材,内容涵盖RDD编程、Spark SQL、Spark Streaming等核心模块。配套的在线教程(如“厦大数据库实验室”网站)提供了详细的实验指导、代码示例和视频讲解,降低了学习门槛。
- 一体化实验平台:为解决Spark环境配置复杂的问题,团队开发了基于Docker的一键部署实验环境,学生可通过浏览器直接访问预配置的Spark集群、Jupyter Notebook和Hadoop生态系统,将学习重心从环境搭建转移到编程实践。
- 丰富的案例库与数据集:课程提供了从经典WordCount到实时日志分析、推荐系统等贴近实际的应用案例,并配套清洗好的公开数据集,帮助学生理解技术如何解决真实业务问题。
二、教学经验与模式创新
在教学实践中,林子雨团队探索出一套行之有效的教学方法。
- “理论-演示-实践”循环模式:课堂讲授核心原理后,立即通过实际代码演示其运行过程与结果,随后学生动手完成针对性实验。这种快速循环强化了学生对抽象概念的理解和动手能力。
- 项目驱动学习:课程后半段引入综合性课程设计项目,如“电商用户行为分析”或“社交媒体热点挖掘”,要求学生以小组形式,运用Spark技术栈完成数据采集、处理、分析与可视化全流程,培养工程协作与问题解决能力。
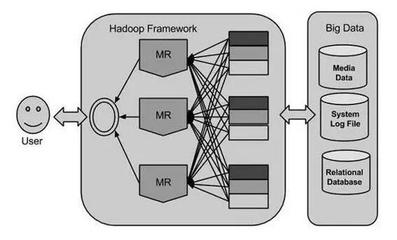
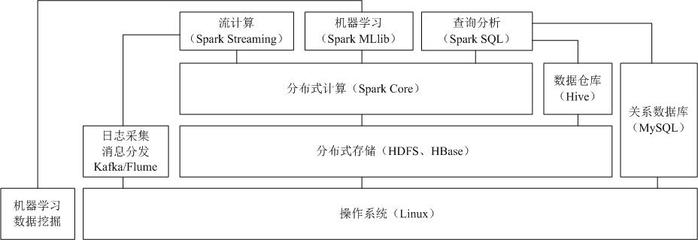
- 注重生态关联教学:并非孤立讲解Spark,而是将其置于Hadoop大数据生态中,厘清Spark与HDFS、Hive、HBase等组件的关系与定位,使学生建立起系统的知识图谱。
三、挑战与应对策略
教学过程中也面临诸多挑战,团队对此积累了相应的应对策略。
- 学生基础差异大:通过提供“前置知识补充包”(包括Linux、Scala/Python基础)和分级实验任务,实现差异化教学。
- 技术迭代迅速:建立课程资源动态更新机制,紧跟Spark社区主流版本,同时聚焦核心、稳定的API与架构思想,避免陷入细节变动。
- 理论与实践脱节:通过引入企业真实场景简化后的案例,并与国内云厂商合作,提供免费的云上Spark实验资源,让学生体验大规模数据处理的实际环境。
四、与展望
林子雨团队的经验表明,大数据技术教学的成功依赖于:高质量且持续维护的开源资源、紧密耦合理论与实践的课程设计、以及对学生工程能力与系统思维的着重培养。随着云原生、AI融合等趋势发展,Spark教学也需向实时计算、图处理、与机器学习库(MLlib)的深度结合等方向深化,并进一步探索产教融合、在线开放课程(MOOC)与线下实践相结合的新模式,以持续为社会输送具备扎实大数据处理能力的高素质人才。
(注:本文内容基于对林子雨教授公开报告、教材及课程网站资源的梳理与解读,旨在分享其在大数据Spark技术教学方面的系统化建设经验。)
如若转载,请注明出处:http://www.sdlysll.com/product/24.html
更新时间:2026-04-12 16:04:20