常用大数据分析工具与核心处理技术概览
在大数据时代,从海量、多源、高速增长的数据中提取有价值的信息,已成为企业决策和创新的关键。这一过程依赖于一系列功能强大、各具特色的大数据分析工具和底层数据处理技术。本文将概述当前主流的分析工具与核心技术,为理解和选型提供参考。
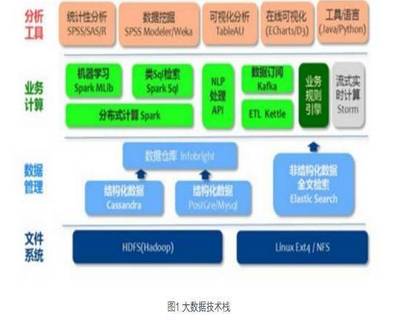
一、常用大数据分析工具
大数据分析工具种类繁多,根据其技术栈和应用场景,大致可分为以下几类:
- 批处理与计算引擎
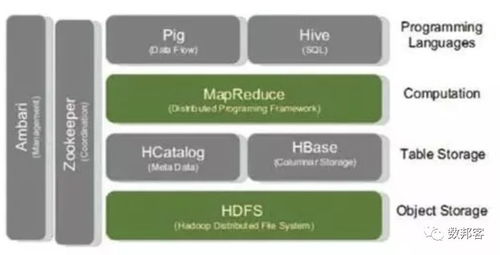
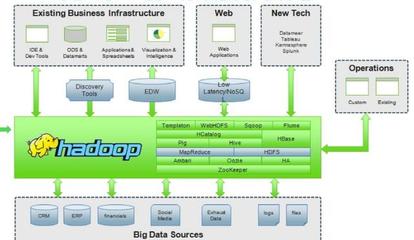
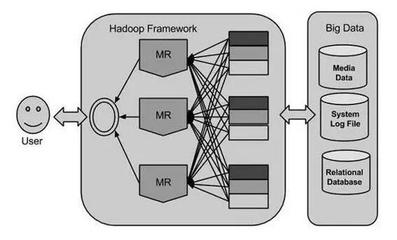
- Apache Hadoop:作为开源分布式系统的基石,其核心HDFS提供海量存储,MapReduce提供批处理计算模型。虽然原生MapReduce因效率问题逐渐被替代,但Hadoop生态依然广泛。
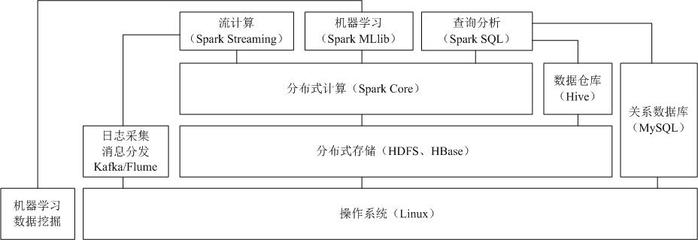
- Apache Spark:目前主流的通用计算引擎。它基于内存计算,速度远超MapReduce,并统一支持批处理、流处理、机器学习和图计算,通过RDD、DataFrame等抽象提供灵活的API。
- Apache Flink:真正意义上的流处理优先引擎,将批处理视为流的有界特例。其低延迟、高吞吐、Exactly-Once的容错保证,使其在实时计算领域占据重要地位。
- 查询与数据仓库工具
- Apache Hive:构建在Hadoop之上的数据仓库工具,可将结构化数据文件映射为数据库表,并提供HQL(类SQL语言)进行查询,降低了使用门槛。
- Apache HBase:一个分布式、面向列的NoSQL数据库,适合实时读写和随机访问超大规模数据集,常作为在线查询的存储层。
- Presto / Trino:开源的分布式SQL查询引擎,可对从GB到PB级别的数据源进行快速交互式分析,支持跨Hive、关系数据库、NoSQL等多种数据源联合查询。
- ClickHouse:开源的列式数据库管理系统,专为在线分析处理而设计,以极高的查询速度著称。
- 流处理与消息队列
- Apache Kafka:分布式流处理平台,常作为高吞吐量的分布式消息队列,是构建实时数据管道和流应用的核心。
- Apache Storm:早期的分布式实时计算系统,擅长无界流数据的处理,延迟极低。
- Apache Pulsar:新一代的云原生分布式消息流平台,集消息、存储和轻量级函数式计算于一体。
- 数据集成与工作流调度
- Apache Sqoop:用于在Hadoop和结构化数据存储(如关系数据库)之间高效传输批量数据的工具。
- Apache Flume:用于高效收集、聚合和移动大量日志数据的分布式服务。
- Apache Airflow:以编程方式编写、调度和监控工作流的平台,通过有向无环图管理复杂的数据处理流程。
- 商业与云端平台
- AWS, Azure, GCP大数据服务:三大云厂商提供全托管的大数据服务套件(如EMR、HDInsight、Dataproc),降低了集群管理和运维的复杂性。
- Cloudera CDH / Hortonworks HDP:提供企业级的大数据平台分发版,整合了Hadoop生态核心组件并增强企业功能。
二、核心大数据处理技术
支撑上述工具高效运行的,是一系列关键的处理技术:
- 分布式存储
- 核心思想是将超大数据集分割成块,分布存储在集群的多个节点上,并通过冗余副本来保证可靠性和可用性。代表技术如HDFS、对象存储(如S3)。
- 分布式计算
- 将计算任务分解为多个子任务,分发到集群的各节点并行执行,最后汇果。MapReduce是经典模型,而Spark的DAG(有向无环图)执行引擎、Flink的流式执行引擎则是更先进的代表。
- 资源管理与调度
- 负责在集群中高效、公平地分配计算资源(CPU、内存等)给多个计算框架或任务。Apache YARN是Hadoop2.0后的核心资源调度器,而Kubernetes正日益成为云原生大数据堆栈的调度标准。
- 数据分区与分片
- 通过合理的分区策略(如范围分区、哈希分区)将数据分布到不同节点,是实现并行计算和负载均衡的基础,能极大影响查询和计算的性能。
- 容错机制
- 大规模集群中节点故障是常态。通过数据副本(如HDFS默认3副本)、计算中间状态持久化(Checkpointing)和弹性重算(如Spark基于RDD血统的重算)等技术,确保作业在故障后能继续或恢复,保障数据一致性和任务可靠性。
- 内存计算与优化
- 通过将数据尽可能保存在内存中进行计算,避免频繁的磁盘I/O,这是Spark等新一代工具性能飞跃的关键。列式存储、向量化执行、查询优化器(如Catalyst)等技术也极大地提升了处理效率。
- 流处理技术
- 与批处理“有界数据”不同,流处理针对“无界数据流”。其核心技术包括事件时间与水位线处理乱序数据、窗口计算(滚动、滑动、会话窗口)、以及状态管理,以保证流计算结果的正确性。
###
大数据分析工具与技术生态日新月异。工具的选择需紧密结合业务场景(是实时监控还是离线报表)、数据特征、团队技能和成本预算。而理解底层的处理技术,则有助于更深入地优化性能、排查问题并设计稳健的数据架构。批流一体、湖仓一体、云原生以及与AI的深度融合将继续引领该领域的发展方向。
如若转载,请注明出处:http://www.sdlysll.com/product/10.html
更新时间:2026-05-08 16:13:12