数据挖掘技能体系与大数据处理技术概览
数据挖掘作为从海量数据中提取有价值信息和知识的关键技术,其成功实施依赖于一套复合型的技能体系,并紧密结合大数据处理技术。以下是数据挖掘所需的核心技能及相关大数据处理技术的详细阐述。
一、数据挖掘的核心技能要求
- 数学与统计基础
- 概率论与数理统计:理解随机性、分布、假设检验、回归分析等,是模型构建和结果评估的基石。
- 线性代数与优化理论:用于处理高维数据、矩阵运算及算法优化,支撑机器学习算法的实现。
- 离散数学:在图论、逻辑推理等方面提供支持,适用于关联规则挖掘等场景。
- 编程与算法能力
- 编程语言:熟练掌握Python(因其丰富的库如Scikit-learn、Pandas)、R(统计建模优势)、SQL(数据查询必备),有时需Java/Scala用于大数据框架开发。
- 算法设计:理解经典数据挖掘算法(如决策树、聚类、神经网络)的原理与实现,并能根据问题定制或优化算法。
- 数据结构与软件工程:高效处理数据,并保证代码的可维护性和可扩展性。
- 领域知识与业务理解
- 结合特定行业(如金融、医疗、电商)的背景知识,能精准定义挖掘目标,确保结果具有实际应用价值。
- 具备数据敏感性和问题转化能力,将业务需求转化为可执行的数据挖掘任务。
- 数据处理与可视化技能
- 数据预处理:熟练处理缺失值、异常值、数据归一化等,保证数据质量。
- 可视化工具:使用Matplotlib、Tableau等工具展示数据模式和结果,辅助洞察与沟通。
- 机器学习与深度学习
- 掌握监督学习、无监督学习、强化学习等主流方法,并了解深度学习框架(如TensorFlow、PyTorch)以处理复杂模式。
二、大数据处理技术的关键支撑
数据挖掘常涉及大规模数据集,因此大数据处理技术不可或缺:
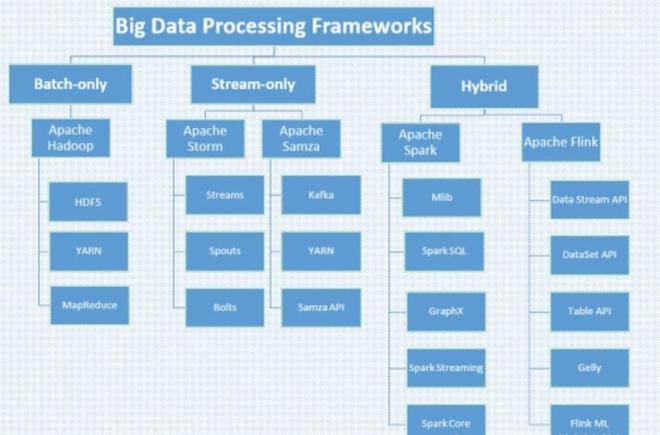
- 分布式计算框架
- Hadoop生态系统:利用HDFS进行分布式存储,MapReduce进行批量数据处理,为数据挖掘提供基础架构。
- Spark:以其内存计算优势,支持快速迭代的数据挖掘算法,MLlib库内置常用机器学习工具。
- Flink:适用于流式数据挖掘,实现实时分析与处理。
- 数据库与存储技术
- NoSQL数据库:如MongoDB、HBase,处理非结构化或半结构化数据,扩展数据源范围。
- 数据仓库:如Hive、Snowflake,支持大规模数据查询与集成,便于挖掘前的数据准备。
- 数据流水线与云平台
- ETL工具:使用Apache Airflow、Kafka等构建自动化数据流水线,确保数据及时可用。
- 云服务:依托AWS、Azure、Google Cloud的大数据服务(如EMR、Databricks),降低基础设施复杂度,提升可扩展性。
- 并行与高性能计算
- GPU加速和分布式算法优化,应对深度学习等计算密集型挖掘任务。
三、技能整合与实践建议
数据挖掘专业人员需将上述技能融会贯通:从业务理解出发,通过大数据技术获取和处理数据,运用数学与编程技能建模分析,最终以可视化方式呈现洞察。建议通过实际项目(如Kaggle竞赛或行业案例)持续锻炼,并关注技术演进(如AI融合、边缘计算),以保持竞争力。
数据挖掘是一个跨学科领域,其成功既依赖于扎实的数学、编程和业务技能,也离不开高效的大数据处理技术作为后盾。随着数据量的爆炸式增长,这两者的结合将愈加紧密,推动从数据中挖掘智慧的新突破。
如若转载,请注明出处:http://www.sdlysll.com/product/9.html
更新时间:2026-05-08 19:01:33