Hive与MapReduce 解析两大核心大数据处理技术的本质区别
在大数据技术生态中,Hive和MapReduce是两种极具代表性且密切相关的处理工具。它们共同服务于海量数据的分析与计算,但在设计理念、使用方式和适用场景上存在根本性的区别。理解二者的差异,对于构建高效、灵活的大数据处理管道至关重要。
一、 核心定位与抽象层级不同
- MapReduce:是一种编程模型和分布式计算框架。它提供了最基础的编程范式(Map和Reduce两个阶段)和运行时环境,让开发者能够编写代码,直接控制数据在集群中的分发、计算和汇总过程。它位于技术栈的较底层,要求开发者具备较强的Java等编程能力,并需手动处理许多分布式计算的细节(如数据分区、节点通信、容错机制)。
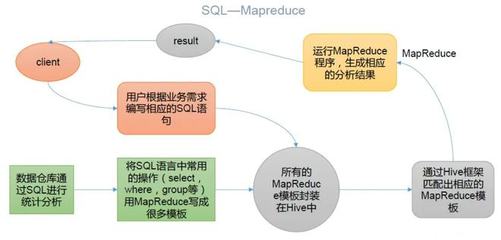
- Hive:是一个构建在Hadoop(通常包括MapReduce、Tez或Spark作为计算引擎)之上的数据仓库工具。它的核心是SQL-on-Hadoop,旨在通过类SQL的查询语言(HiveQL)来操作存储在HDFS上的大规模数据集。Hive将用户编写的HiveQL语句“翻译”(编译)成一系列MapReduce任务(或其他引擎的任务)来执行。因此,Hive位于更高的抽象层级,主要面向数据分析师和SQL开发者,隐藏了底层复杂的MapReduce编程逻辑。
二、 数据处理范式:代码 vs. 声明
- MapReduce:属于过程式/指令式编程。开发者需要明确指定“如何做”——即如何分割输入数据,Map函数如何处理每条记录,如何对中间结果进行排序和分区,以及Reduce函数如何聚合最终结果。这提供了极高的灵活性,但开发效率较低。
- Hive:属于声明式查询。用户只需声明“想要什么”(例如,
SELECT department, AVG(salary) FROM employee GROUP BY department),而无需关心这个查询是如何在分布式集群上一步步执行的。Hive的优化器会负责生成最优的执行计划。这极大地提升了开发效率,降低了使用门槛。
三、 性能与执行效率
- MapReduce:作为底层执行引擎,其性能高度依赖于开发者编写的代码质量。优秀的MapReduce程序可以非常高效。但由于其基于磁盘的shuffle(数据混洗)机制和多次I/O操作,对于交互式查询和迭代计算场景,延迟通常较高。
- Hive:在默认使用MapReduce作为执行引擎时,其执行效率通常低于手写的、高度优化的MapReduce程序,因为自动生成的作业可能不是最优的。Hive的价值在于用一定的性能损耗换取极致的开发效率。更重要的是,现代Hive支持将执行引擎替换为Apache Tez或Apache Spark,这些内存计算框架能大幅提升HiveQL的查询速度,弥补了传统MapReduce引擎的不足。
四、 主要应用场景
- MapReduce更适用于:
- 需要高度定制化、复杂逻辑的批处理任务。
- 处理非结构化的原始数据(如日志文件、文本)。
- 作为其他高级计算框架(包括Hive)的底层执行引擎。
- Hive更适用于:
- 基于结构化或半结构化数据的离线批量分析(ETL、报表生成、即席查询)。
- 需要频繁使用SQL进行数据汇总、统计和查询的场景。
- 构建企业级数据仓库的Hadoop层。
五、 关系:互补而非对立
简单来说,可以将Hive看作是MapReduce(及其他引擎)的一个“翻译官”和“封装器”。MapReduce是“发动机”,提供强大的分布式计算能力;Hive是“方向盘和仪表盘”,让用户能以更熟悉、更便捷的方式(SQL)来驾驶这辆强大的数据计算“汽车”。
在实际的大数据技术栈中,二者常常协同工作:Hive作为主要的数据查询与分析接口,而MapReduce(或Tez/Spark)作为其默认或可选的执行引擎,负责完成繁重的实际计算工作。随着技术发展,Spark等更快的引擎正逐渐成为Hive更常用的后端,但理解MapReduce的原理,依然是深入掌握大数据处理技术的基石。
如若转载,请注明出处:http://www.sdlysll.com/product/8.html
更新时间:2026-05-08 19:08:21